World Happines Report (WHR) 2017
- Data source: World Happiness Report, using only the year 2016.
- Goal: understand the drivers behind happiness, not just the final score.
- Reference points: two hypothetical countries,
"utopia"and"dystopia". - Interpretation:
utopiatakes the best observed value for every feature, whiledystopiatakes the worst.
Imputation Process
Many countries have missing values in 2016, so the project required a dedicated imputation strategy.
Why imputation was needed
- Several countries are missing one or more features in 2016.
- First pass: use previous years and average historical records when they exist.
- Limitation: countries without historical records cannot be handled in that first step.
- Temporary decision: leave those countries aside until a second-stage model is available.
How the integrated score was built
- Standardize the usable data so each feature lies between
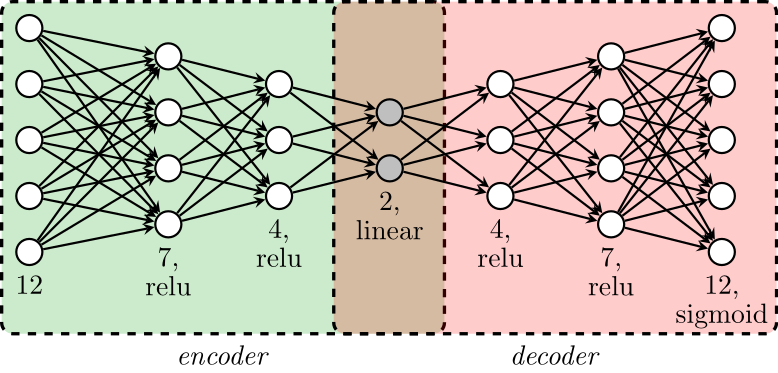
0and1. - Train an Autoencoder (AE) and use the encoder to project countries into a two-dimensional non-linear latent space.
- Use Principal Component Analysis (PCA) in that latent space to define the main one-dimensional ordering.
- Project
utopiaanddystopiaonto that ordering after training. - Define an integrated score from
0to10, wheredystopia = 0andutopia = 10.
How the missing countries were recovered
- Train a Random Forest (RF) on countries that already have an integrated score.
- Use that RF to estimate the score of countries with missing values and no historical records.
- Feed the final scores through the decoder part of the AE.
- Use the decoder reconstruction as the final imputation for the missing 2016 values.
This approach is more informative than simply averaging historical values, because the AE can capture more complex non-linear relationships among countries. An imputed version of the data was created as part of this project.
Workflow summary
- Train an AE and use its encoder.
- Use PCA in the latent space to assign an integrated score to each country.
- Use a RF to estimate the integrated score of countries with missing values.
- Use the AE decoder to reconstruct the missing features.
Visualizations
Maps and Histograms
It is the national average response to the question: "Please imagine a ladder, with
steps numbered from 0 at the bottom to 10 at the top. The top of the ladder represents the best possible life for you and the bottom of the ladder
represents the worst possible life for you. On which step of the ladder would you say you personally feel you stand at this time?"
The measure is the national average responses to two questions: "Is corruption widespread throughout the government or not?" and
"Is corruption widespread within businesses or not?" The overall perception is just the average of the responses.
Data Visualization in Latent Spaces
Choose how to display the dimensionality-reduction view below.
Some comments about the world
Main takeaways
- Global inequality is enormous.
- Qatar reaches a GDP per capita of roughly 136,000 USD, while much of the world remains below 20,000 USD, and Burundi does not reach 400 USD.
- In parts of America and Africa, household income inequality is especially severe.
- Some countries combine low freedom with high sadness and anger.
- Large areas of the map turn red when we look at perceived corruption or generosity.
- There are also more hopeful signals.
- Countries such as Rwanda or Somalia stand out for their efforts against corruption.
- Much of the Americas appears stronger in happiness and enjoyment.
- Across much of the world, people still report that they have someone to count on in times of trouble.
Irving Gómez-Méndez
Assistant Professor of Artificial Intelligence
I work at the intersection of statistics, machine learning, causal reasoning, and interactive quantitative software.